
On 29th of November 2022 at the last re:Invent, AWS announced a new exciting security service – Amazon Security Lake (currently in preview), supported by major players in the industry like Cisco and Splunk. May you be a SysOps engineer, security administrator or data engineering manager looking to have improved security management of your AWS organization – this may be the service for you.
Security Lake empowers your organization with an all-around capability to manage and normalize all the security data in one centralized data lake, supporting data records in Parquet and Open Cybersecurity Schema Framework (OCSF) standard. Relying on that standard, the key feature of the Security Lake service is that now both AWS service specific and external data sources are transformed into this common data format for downstream consumption, for example for threat detection and incident response automation. AWS example subscribers include OpenSearch, Athena and SageMaker, but developers are free to write their own OCSF-compatible subscribers for the Security Lake.
Laying the context
Proactive measures in cyber risk management are required while organizations continue to be more and more dependent upon digital services. In practice, it leads to an increasing supply of cyber security tool solutions. However, for a security engineer whose tasks among others include automatic remediation of security incidents, the abundance of different tools and data formats distracts from doing the real detection and incident response automaton work. And this is not the end of the data-related troubles burdening the cybersecurity engineers in their daily work.
Currently the sector of cybersecurity data management faces issues such as vendor log format incompatibility, abundance of mutually incompatible security formats, security data ownership and lifecycle concerns, solution provider lock-in due to data schema incompatibilities, open-source standard underutilization and solution cost ineffectiveness. This diverse set of issues motivates a development of a solution in the cybersecurity sector in order to improve the general cybersecurity quality and development efficiency in the organization.
The solution to the beforementioned diverse set of issues should facilitate the operationalization, management, storage and consumption cybersecurity data while keeping storage, querying and ingestion costs at minimum and facilitate the threat detection automation and integration with both third party security information and event management (SIEM) as well as open-source tools.
Why does it matter?
According to Forbes, cyber-crime is growing exponentially, increasing by 2.5 trillion USD in cost in the next 2 years. There isn’t a single day without some news announced on cyberattacks and major vendors in the industry like Google, Amazon and Microsoft have launched their own security tools. In terms of AWS offering, AWS Security Hub has been the most comprehensive security solution from AWS so far. But has it proved itself to be the king of the cybersecurity services demanded in the industry?
If you have used AWS Security Hub before, you may have experienced that for example its dashboard update interval could be shortened in order to be more relevant in case of real-time incident situations. Also security engineers may be burdened with issues that in reality stem from inconsistencies of data formats between vendors. However on the other hand, the idea of having a central security score definitely facilitates the understanding of how well positioned an organization is in securing their AWS accounts. AWS has enabled the adoption of third-party datasets for improved cloud account cybersecurity, and conveniently integrated this as part of the beforementioned Security Hub security score (for example, through the GuardDuty service).
But what if the customer has some specific datasets to be leveraged that are either generated by their own applications or rely on historical trends from 3rd party providers? And what if they need possibly near real-time detection of these events that won’t be visible to the human eye and quick access to the enriched historical data? Today there is not one service that does all that in AWS, but the Security Lake service can get you very close to meeting that requirement.
Problem faced by security engineers currently
Every week you can read news about how AI is automating human jobs. Nevertheless, in order to be able to leverage AI and for humans to do more meaningful work, the data needs to be homogenized. Most of the cybersecurity teams and analysts in the world still clean and transform their data manually and that can lead to fatigure, burnout and boredom with work. So the need for standardization and automation of cybersecurity data is evident. With regards to implementing standardization on AWS, the first framework that may come to mind is the AWS Well-Architected framework.
Amongst others, the Well-Architected framework refers to the ready-made playbooks for incident responses and more specifically, SEC04-BP04 Implement actionable security events mentions runbooks (enabling consistent and prompt responses to well understood events by documenting procedures in runbooks) and playbooks (predefined steps to perform to identify an issue).
![]() Learn more and book a Well-Architected Review
Learn more and book a Well-Architected Review
However, there's a difference between automating the remediation of a Security hub finding (see the image below) and a real security attack scenario.
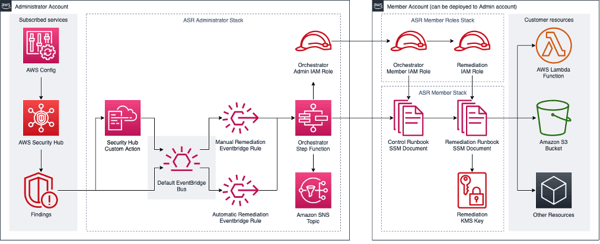
What would be the specific steps implemented in the runbook be in the case of leveraging 10 different cybersecurity data sources of different formats? Although AWS Solutions Library includes sample solutions for automatic security incident remediation (click here for an example), since the concrete way to resolve an attack may not be predicted beforehand, there wouldn't be a ready-made playbook or pre-deployed AWS Lambda service for it. So if as a result the security engineer has to manually parse third-party vendor data, the speed of the activity could cost the organization under attack millions of euros. Oops...
Enter Security Lake
And this is where Security Lake enters the scene again – fast (hourly) data homogenization that could be used for near real-time incident remediation. In a real life-scenario the Cloudwatch alarms or SNS messages will trigger appropriate responses for more simple automations, but for more complex responses the security team has to step in, turning to the Security Lake hourly generated data for further insight or leverage a pre-built automation on top of that data. Therefore, the Security Pillar currently doesn’t seem to cover more complex attack scenarios for which more complex, possibly security data driven applications need to be developed and deployed.
Let’s now take a look on how the cloud security posture, previously controlled by AWS Security Hub is enhanced with the introduction of Security Lake.
Security synergies – Combining Security Hub and Security Lake
The Security Hub and Security Lake are complementary services meant to improve the security posture in your entire AWS organization. Let’s look a bit closer at the similarities and differences between them.
Security Hub itself is not collecting any data but rather focusing on compliance and snapshotting the overall security posture of the organization. On the other hand, the main focus of Security Lake is can be summarized as CONA which describes the different phases of cybersecurity data management:
- Centralize (data governance)
- Optimize (storage and querying)
- Normalize (data formats)
- Analyze (clean data in OCSF format)
Security Hub has a central dashboard, but for Security Lake you need to add an OpenSearch dashboard as subscriber, so no inbuilt system dashboard included.
From similarities, both Security Hub and Security Lake use one particular data format and they can integrate with third-party providers. The difference is that Security Lake is based on OCSF data format which is open-source, whereas Security Hub leverages ASFF (AWS Security Finding Format) which is proprietary to AWS.
Security Hub supports custom data sources as well so an organization can get security findings from all supported Security Hub partners.
Both services unload your development team from building custom integrations with individual AWS services such as Macie, GuardDuty or Inspector. For some automation to be developed, the developer just needs to integrate with Security Hub or Security Lake directly.
Making these two services work in tandem creates a strong base for enhancing your security defenses against any malicious actors. Security Hub could be encapsulated as “Security todayâ€, focusing on general principles, guidelines and security hygiene whereas Security Lake could be summarized as “Security for tomorrow†in the sense that the data acts like a tool on which predictive automations, not just descriptive automations can be built on top of.
Now that we have a clear understanding where Amazon Security Lake is positioned, let’s summarize why it would be a good idea to start using it for your AWS organization
Why adopt Security Lake to your AWS organization?
1. Solves the challenge of security data format heterogeneity
2. Easy for developers to work because it has a central standard that it conforms to
The consumer application developed just needs to integrate with Security Lake (by becoming a subscriber). That way, building a custom solution leveraging Security Lake is a straightforward process.
3. Easy to test and launch
It takes around 5 minutes to launch the service and in 1 hour you will already have cleaned data, possibly from many accounts and regions ready to be checked out.
4. Scaling security throughout the organization – protection also for your application data
For custom sources, it just requires an application that writes some data to S3 in certain partitioned format, for example using this library (former AWS Data Wrangler), but any service that writes the data in the correct way is supported.
5. Future-oriented, bulletproofing against future attack vectors possibly driven by AI
The topic of cloud and cybersecurity is becoming increasingly more important and conventional rule-based systems won’t be enough to handle the complex attacks of the future. Imagine some synthetic algorithms with a pseudo-intelligence of that of GPT-4 or ChatGPT that could possibly be used to generate (new trends are the generative models) new synthetic attack vectors on the fly. These patterns can obviously change over time but might be very complex for humans to detect.
6. No additional cost
Pricing is dependent on the use of underlying services (mostly AWS Glue). Keeping it running in 7 regions with a few data sources in a minimal configuration capped the monthly cost under 5 dollars, originating from the other services (no cost for Security Lake service). Read more about the pricing.
How to deploy Security Lake
![]() Getting started with Amazon Security Lake
Getting started with Amazon Security Lake
Since currently Security Lake is in preview mode and not generally available, there is no infrastructure-as-code deployment for it just yet. See this Github issue to follow the Terraform support.
Use case: How to synergize Security Lake data and build an advanced security threat detection and remediation application
The key questions we are interested in answering and that would significantly increase the cybersecurity protection level for an organization are the following:
- Which cyberattack types are the organization’s AWS accounts most vulnerable to? (Future-looking perspective)
- Is any of the AWS organization accounts under a cyberattack now, and if so, which under which type of a cyberattack? (Current status)
In order to achieve the ability to answer these questions, a solution entails cybersecurity data augmentation and leveraging AI models (deep learning, a form of machine learning where deep neural networks are utilized).
As you may know these models work the best if we have sufficient amount of relevant data for them to learn on. So where to get this data? Since the main features of Security Lake include data collection, governance, normalization and augmentation, we have a natural position to solve these problems using that data. In data science and machine learning field, solving a problem usually starts with a descriptive data analysis step to get to know what data we have available to solve the problem.
Let’s give a short glimpse into how the data on Security Hub findings in Security Lake looks like:
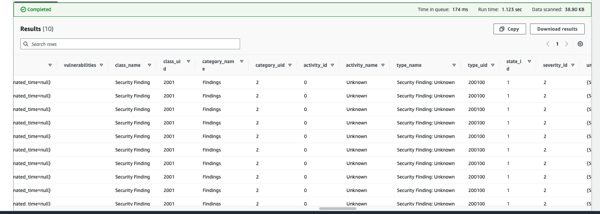
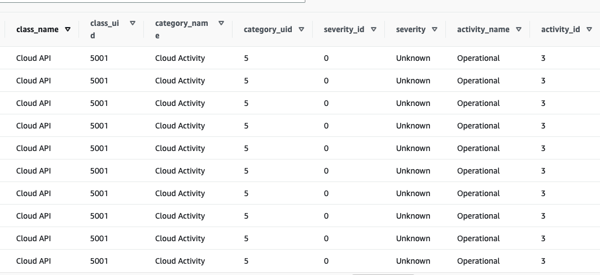
We notice that the answers to the questions stated earlier can not be directly answered with the help of this data only. Therefore, it is recommended to augment this dataset by including at least the VPC Flow logs (packet level data) and Route53 data and in addition, if needed, to possibly subscribe to some of the relevant Security Lake third party integrations such as Cisco and Splunk. As a reference, what kind of data would be most helpful, it pays off to understand what data is provided by the benchmarks such as ISOT-CID and CIC-IDS datasets for example. The latter enhances the model with the power to predict the type of cyberattack:
- Denial-of-Service (DoS)
- Cross-site Scripting (XSS)
- Distributed Denial-of-Service (DDoS)
- Directory Traversal
- SQL Injection
- Backdoor
- Infiltration Attack
- Botnet
Now, equipped with a significantly augmented cybersecurity dataset regarding the cyberattack vulnerabilities and attack patterns, the next step of the solution then entails the conversion of all this Security Lake data into images, and (re-)training a DCGAN - a deep convolutional generative adversarial network.
A general adversarial network is built on the idea of a generator that does the data generation (generating real or fake data, trying to fool the discriminator) and a discriminator that tries to correctly separate the real and fake data, exemplified by the simplified diagram below:
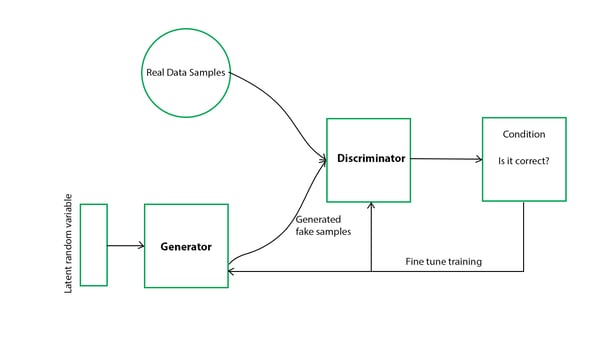
Reference: Agrawal, R. 2021. An End-to-End Introduction to Generative Adversarial Networks (GANs). Analytics Vidhya.
The idea beyond this kind of generative modelling is to learn the “simplified†representation of the security data in order to enhance the understanding of it for the security team and generate new security data, similar to a possible future cyber attack data, for enhancement of threat detection.
We can then train this neural network in an adversarial fashion and use the resulting models for threat detection. Disclaimer: It may require some usage of pre-trained models on vulnerability databases and high computational resources in the training phase, dependent on the required performance of the model.
The advantage of DCGAN compared to other supervised learning models is that it tackles the issue of needing labeling of classes, i.e. the identification of “attack†VS “no attack†and sub-classifying the attack type for new data, since this has been generated similarly to how it is in the existing data. The model will be able to generate new data similar to the known attack patterns as well as handle unknown attack patterns. This knowledge can then be leveraged in this application directly.
We can then deploy the DCGAN generator network to generate new security training data that looks like the data generated by Security Lake and use it also, for example, for visualization purposes to understand better the structure of the data.
For the direct integration with Security Lake, we can deploy the DCGAN discriminator network for making inference on new featurized data obtained from the Security Lake. Featurization is the process to convert varied forms of data to numerical data which can be used for basic machine learning algorithms. It can be deployed as a subscriber for the Security Lake. That AI-powered subscriber application is then used to answer the two key questions outlined in the problem set-up.
As a summary, we have shown the idea of how to use Amazon Security Lake to govern, collect and augment AWS organization cybersecurity data that results in the enablement of the link between the AWS account security vulnerabilities and cyberattack patterns.
With this ability, any possible cyberattack vulnerability or real attack pattern can be detected, before it could cause any real damage to the organization AWS accounts. With the power of intelligent predictions, both old and new types of cyberattacks can be avoided and overcome with minimal unpredicted costs to an organization.


